
Robots.txt filen giver søgemaskinerne (og andre systemer) direktiver angående crawling af din hjemmeside.
Eksempler på direktiver:
- Blokering for crawling af specifikke filer, sider, eller undermapper
- Blokering for crawling af et helt domæne (inkl. protokoller og subdomæner)
- Henvisninger til dine sitemaps
Denne .txt fil finder du i dit (sub)domænes root directory (hvis du altså har en).
Som også er mappen der kaldes noget knapt så charmerende på dansk, nemlig “rodmappe”. For mig giver det både associationer til en rodet mappe, rodfrugter, eller begge dele. Men det er vidst en anden snak 🙂
Fejl i opsætningen af ens robots.txt kan være en meget dyr fest.
Det kan bl.a. helt forhindre søgemaskinerne i helt at crawle din hjemmeside. En fejl du nok først ville finde ud af, når det var for sent.
Eller hvis du i god tro bruger robots.txt filen til at blokere (disallow) for crawling af URL adresser, med værdifulde eksterne backlinks, så søgemaskinerne ikke kan tilgå siderne, og dermed heller ikke overføre link værdien fra de eksterne links. Det samme gælder for dine egne links til andre hjemmesider.
Men bare rolig, i denne guide vil du blive guidet fra A-Å i hvordan du sikrer opsætningen af din robots.txt fil, og sikrer at optimal udnyttelse af dit SEO potentiale. Hvad end du har en robots.txt i forvejen eller ej.
Sådan finder du din robots.txt fil
Det gør du ved blot at gå til dit /robots.txt URL adressen på dit domæne (eksempel.dk/robots.txt).
Det gælder os for dine subdomæner (www/non-www) og protokoller (HTTP/HTTPS).
Nemmere bliver det nok ikke…
Hvis du ikke ser en fil, betyder det du ikke har en (der er live i hvert fald).
De 8 dyre fejl i robots.txt
Først og fremmest skal vi sikre os, at du ikke begår nogle typiske fejl i din robots.txt.
Det er dog ikke mærkeligt hvis du er kommet til det, da nogle af anbefalingerne ikke altid giver helt mening.
Selv for nogle af verdens største hjemmesider bruger ikke direktiverne ud fra Googles seneste anbefalinger. Der kommer et eksempel senere i guiden.
Det hjælper heller ikke på det, at der ikke findes universelle best-practices der passer alle. Det er i virkeligheden er det op til den enkelte, at vurdere hvad den bedste opsætning er.

1. Blokering af søgemaskiner
De fleste bruger også robots.txt til at blokere søgerobotterne, så de ikke kan crawle specifikke sider eller undermapper.
Formålet er at optimere crawlingen af sin hjemmeside, og samtidig bevare eller spare på sit “crawl budget”. Og budgettet ønsker vi så vidt muligt at bevare til de vigtigste sider på vores hjemmeside.
Søgemaskinerne crawler nemlig ikke en ubegrænset mængde URL adresser på et domæne, og ens budget er derfor begrænset.
Dit crawl budget vurderer søgemaskinerne bl.a. ud fra størrelsen af din hjemmeside, hastigheden, hyppigheden af evt. fejlkoder, populariteten målt på besøgende, backlinks, og hvor ofte hjemmesiden opdateres med nyt indhold.
Og det giver jo super god mening, da det alternativt ville kræve uendelige ressourcer. Men i den virkelige verden, har selv Google (og andre søgemaskiner) sine begrænsninger 🙂
Hvis du har en mindre hjemmeside er crawl budgettet dog ikke noget du skal bekymre dig så meget om.
Lad os hurtigt gennemgå et eksempel på en robots.txt fil.
Eksempel på robots.txt:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://ideelt.dk/post-sitemap.xml
Sitemap: https://ideelt.dk/page-sitemap.xml
Sitemap: https://ideelt.dk/category-sitemap.xml1. linje: User-agent: *
Denne linje specificerer hvilken user agents der skal følge reglerne (f.eks. googlebot).
Stjernen indikerer, at reglen gælder for alle robotter. Hvis den f.eks. udskiftes med “googlebot” vil det betyde, at reglen kun gælder for Google.
2. linje: Disallow: /wp-admin/
Denne linje specificerer hvilke URL adresser reglen gælder for.
Her gælder det om at være opmærksom, da du i værste fald kan blokere for hele din hjemmeside, eller vigtige dele af den.
En blokering af en hel hjemmeside vil se således ud:
Disallow: /
Hvis du f.eks. ønsker at blokere en hel undermappe. Det kunne være dine søgeresultatsider. Så kunne de se sådan her ud:
Disallow: /search
3. linje: Allow: /wp-admin/admin-ajax.php
Denne linje specificerer en undtagelse fra reglen i anden linje.
På den måde kan du overskrive dine egne regler. Smart ikke?
5-7. linje: Sitemap: https://ideelt.dk/post-sitemap.xml…
Hver linje henviser til et sitemap.
TIP: Hvis du har et sitemap index, kan du blot nøjes med at tilføje det.
2. Ugyldige wildcards
Ugyldige wildcards kan også være fatale for din organiske trafik.
Her er en tabel over de forskellige wildcards, og eksempler på hvad de matcher og ikke matcher:
| 🔗 URL-sti: | ✅ URL-sti matcher: | ❌ URL-sti matcher ikke: |
| / | Alle URL adresser | |
| /* | Alle URL adresser | |
| /fisk* | /fisk /fisk.html /fisk/laks.html /fiskehoveder /fiskehoveder/mums.html | /Fisk.asp /havkat /?id=fisk |
| /fisk/ | /fisk/ /fisk/?id=altting /fisk/laks.htm | /fisk /fisk.html /Fisk/Laks.asp |
| fisk/ | /fisk/ /fisk/?id=alle /fisk/laks.htm | /fisk /fisk.html /Fisk/Laks.asp |
| /*.php | /filnavn.php /folder/filnavn.php /folder/filnavn.php /folder/filnavn.php?parametre /folder/alle.php.file.html /filnavn.php/ | / (selv hvis den er knyttet til /index.php) /windows.PHP |
| /*.php$ | /filnavn.php /folder/filnavn.php | /filnavn.php?parametre /filnavn.php/ /filnavn.php5 /windows.PHP |
| /fisk*.php | /fisk.php /fiskehoveder/havkat.php? | /Fisk.PHP |
Bemærk at du ikke nødvendigvis behøver at bruge * (stjerne) for enden af en URL-sti.
F.eks. så ville “/fisk” også gælde for “/fiskemad” eller “/fiskehandler-koebenhavn”.
3. Blokering af sider der bør bruge noindex
Undrer du dig over, hvornår det giver mening at blokere sider i robots.txt, kontra at bruge noindex?
Umiddelbart ligner det jo at de gør en og samme ting, bare teknisk på hver sin måde.
Den helt store forskel er, at robots.txt filen ikke garanterer, at en side ikke bliver indekseret (f.eks. hvis et andet domæne linker til den.)
Du blokerer blot for adgangen til crawling af siden.
Hvis du bruger noindex, giver du stadig adgang for søgemaskinerne til at crawle siden, men fortæller dem blot på vejen ud, at den ikke skal indekseres.
Hvad, hvordan (og hvornår?) bør robots.txt så bruges kontra noindex?
Det kommer vi også ind på længere nede i guiden.
4. Blokering af sider der bruger noindex
Mange begår den fejl at blokere sider der samtidigt bruger noindex tagget.
Umiddelbart lader det måske til at give god mening. Hvis man gør begge dele, så må det jo betyde, at chancen for en side ikke bliver indekseret bare er større. Hurra!
…Men tværtimod, så betyder det faktisk, at du risikerer at fastlåse indekseringen af en side.
Det skyldes at når du blokerer for søgemaskinernes mulighed for at crawle siden, blokerer du også for søgemaskinernes mulighed for at indlæse noindex tagget på siden.
Det betyder at en side stadig kan risikere at blive indekseret, hvis en anden hjemmeside linker til den.
5. Ligger under forkert protokol og/eller subdomæne
Som nævnt tidligere, skal din robots.txt fil ligge i rodmappen for dit domæne.
Hvis din hjemmeside f.eks. bruger HTTPS protokollen og WWW. subdomænet, skal det se således ud:
- https://www.eksempel.dk/robots.txt.
Men hvis du ved en fejl ligger din robots.txt et andet sted. I dette tilfælde under en anden protokol eller/og subdomæne. F.eks. under HTTP i stedet for HTTPS:
- http://www.eksempel.dk/robots.txt.
Så vil robots.txt kun være gældende for http://www.eksempel.dk/robots.txt og ikke din hjemmesides rigtige adresse, nemlig https://www.eksempel.dk/robots.txt i det her tilfælde.
Det samme gælder også for subdomæner, f.eks. https://shop.eksempel.dk/robots.txt. I dette tilfælde ville robots.txt være gældende for https://shop.eksempel.dk/robots.txt, og ikke https://www.eksempel.dk.
6. Manglende henvisning til sitemaps
Ved at linke til dine sitemaps i din robots.txt, gør du det nemmere for søgemaskinerne at finde dine sitemaps. Og dermed crawle, indeksere, og ultimativt eksponere din hjemmeside i søgeresultaterne.
Eksempler:
Sitemap: https://eksempel.dk/post-sitemap.xml
Sitemap: https://eksempel.dk/page-sitemap.xml
Sitemap: https://eksempel.dk/category-sitemap.xml
Og så giver det også en nem og let tilgængeligt oversigt, over dine sitemaps.
TIP: Hvis du er i tvivl om du har nogle sitemaps i dag, eller hvor du finder dem, har jeg lavet et hurtigt skriv om det her.
7. Indeholder noindex direktiv
Google har ikke understøttet noindex direktivet i robots.txt siden d. 1 september 2019.
Eksempel:
Noindex: side-der-oenskes-noindexed
Hvis du ikke var klar over dette, og stadig bruger direktivet i dag, så er der risiko for du har uønsket sider indekseret i søgemaskinerne.
Løsningen er at få implementeret noindex tagget på selve siderne i stedet.
8. Forkert navngivning af fil
For at din robots.txt fil er gyldig, skal den navngives præcis “robots.txt”.
Altså ikke med f.eks. stort begyndelsesbogstav eller andet (f.eks. Robots.txt).
Således at URL adressen for filen er “eksempel.dk/robots.txt”, alt efter hvad du bruger af protokol og subdomæne.
Sådan finder du URL adresserne til din egen robots.txt
Det første vi skal er at finde siderne du ikke ønsker skal crawles.
Og her kan der hurtigt opstå tvivl omkring om hvorvidt en URL bør blokeres via robots.txt eller ej.
Selv større sites som såsom HubSpot anbefaler brug af robots.txt til at forhindre sider i at blive indekseret:

Selvom Google ikke garanterer det er tilfældet:

Dog skriver de at siderne sandsynligvis ikke vil blive indekseret, men det er ingen garanti. Derfor anbefaler de noindex til det i stedet, og fraråder brug af robots.txt til at forhindre duplikeret indhold:

Men hvornår bør robots.txt, noindex, eller endda canonicals så bruges, når en side ikke ønskes indekseret?
Svaret er det populære; det kommer an på…
Brug nedenstående illustration til at finde svare, og se uddybelse af løsningerne nedenunder:

Løsning 1 (kodeordsbeskyttet):
Den eneste måde at være 100% sikker er ved at gemme siden bag en login-side.
Løsning 2 (canonicals):
Lav canonical(s) til den originale side.
Eksempel:
F.eks. i en varekategori på en webshop, hvor en sortering- eller filtreringsfunktion genererer unikke indekserbare URL adresser (parameter URLs), og dermed duplikeret indhold.
Canonicals hjælper søgemaskinerne med at vælge originalen, og nedsætter derfor risikoen for duplikeret indhold.
Samtidigt vedvarer du værdien fra eksisterende- og potentielt fremtidige backlinks.
Løsning 3 (noindex):
Noindex kan være det bedste valg.
Hvis du har en mindre mængde URL adresser, vil det umiddelbart heller ikke have de store konsekvenser for dit crawl budget at tillade crawling af siderne.
Det er også Googles primære anbefaling kontra robots.txt, når det kommer til at undgå indeksering af sider (der ikke er kodeordsbeskyttet):

OBS! Hvis du kom hertil fra “Mange > Er URL adresserne allerede indekseret? > Ja” skal du efterfølgende huske at blokere for URL adresserne med robots.txt, når de ikke længere er indekseret i Google (og evt. andre søgemaskiner).
Altså når siderne er blevet crawlet efter implementeringen af noindex tagget, og dermed også fjernet fra søgemaskinerne.
Hvor lang tid det tager afhænger af mange variabler. Jeg anbefaler at du blot skemalægger et hurtigt tjek dagligt eller ugentligt, indtil du ikke længere ser siderne i dine udvalgte søgemaskiners indekser.
Men der er måske en hurtigere og smartere løsning.
Hvis URL adresserne ligger i specifikke undermapper (f.eks. /sider-du-oensker-at-ekskludere), kan du alternativt fjerne dem manuelt i Google Search Console (og Bing Webmaster Tools) i stedet for noindex.
I det tilfælde kan du springe noindex over, og gå direkte til løsning 4 (bruge robots.txt).
MEN:
- Hvis siderne ikke er i undermapper, men er godt spredt, kan det være for tidskrævende at fjerne dem med værktøjerne, og noindex kan alligevel være at foretrække.
- Bing gør det kun muligt at fjerne enkelte sider. Så har du mange URL adresser, kan det hurtigt blive en meget tidskrævende opgave at fjerne dem derfra.
OBS! Hvis du vælger at bruge værktøjerne, så vær varsom. De kan potentielt fjerne hele din hjemmeside fra søgemaskinerne, hvis du laver fejl.
Brug dem derfor kun hvis du har helt styr på dem. Du kan læse mere om Googles værktøj her, og Bings værktøj her.
Løsning 4 (robots.txt):
Blokering i robots.txt kan være det bedste valg.
Hvis du har en større mængde URL adresser, kan dit crawl budget risikere at blive spildt på uønskede sider.
Selvom det sandsynligvis ikke vil ske, så er ulempen sammenlignet med noindex, at du stadig risikerer en eller flere af dine sider bliver indekseret.
Men er alternativet at søgemaskinerne skal crawle tusindvis af irrelevante URL adresser, så er det muligvis det værd.
Vigtigt! Undgå at miste værdien af eksisterende (og potentielt fremtidige) backlinks
Uanset om du vælger løsning 3 (noindex) eller 4 (robots.txt), så vil du miste værdien af eksisterende og fremtidige potentielle backlinks der peger til URL adresserne.
Google viderefører nemlig ikke linkværdi til en side, der har været noindexed i en længere periode (ingen ved hvor lang tid det tager).
Og aldrig for sider blokeret i robots.txt.
Om det så kan betale sig helt at undlade implementeringen af en af de to, afhænger af om konsekvenserne ved ikke at gøre det, vejer mindre end værdien af de eksisterende og potentielle backlinks.
Desto flere URL adresser du lader forblive indekseret, desto mere vil det koste på crawl budgettet, og desto mere duplikeret indhold vil du potentielt få.
Hvad der er det rigtige at gøre afhænger af din hjemmeside.

Som hovedregel vil jeg mene at der skal en overbevisende mængde af kvalitets backlinks til før det kan betale sig.
En god måde at vurdere det på, er også at kigge på den eksisterende backlink trend for siderne.
Hvis du har sider eller undermapper du ønsker at blokere, der har fået en væsentlig og kontinuerlig mængde trafik over en længere periode (f.eks. 3 år), uden at ryste nogle særlige backlinks af sig. Ja, så er sandsynligheden for der pludselig kommer backlinks til nok også meget lille.
Og hvis der er tale om en større mængde URL adresser, så giver det nok bedst mening at bruge robots.txt. Den mindre mængde sider der måske bliver indekseret, vejer nok ikke op for det sparet crawl budget.
Validering af robots.txt (og tilføjelse til Google Search Console)
Når du er blevet færdig med opsætningen af din egen fil, skal vi blot sikre os, at den ikke indeholder nogle fejl og mangler.
Det gør vi med hjælp fra dette værktøj i Google Search Console.
Det kræver at du allerede har opsat din hjemmeside i Google Search Console. Hvis ikke det er tilfældet, kan du oprette en konto her.
Når du er logget ind, vil du se følgende side:

Hvis du allerede ser en robots.txt i feltet, så betyder det bare, at du allerede har en robots.txt fil, eller har haft en Google tidligere har opsnappet.
Sådan gør du:
- Kopier teksten fra din robots.txt fil og indsæt i feltet, hvad end der er en tekst i forvejen eller ej (se pil 1).
Vi får med det samme mulighed for at se evt. fejl eller advarsler (se pil 2): - Kopier eksempler på alle de URL adresser du enten har disallowed eller allowed, og test dem en efter en:
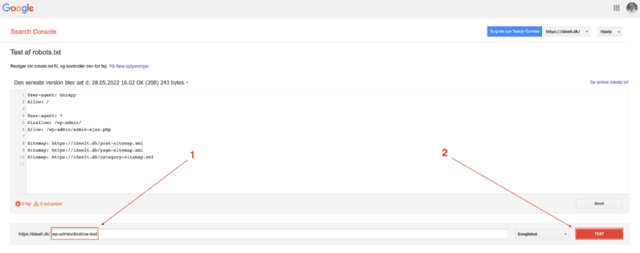
Resultat:

Resultatet er som forventet.
Nemlig at /wp-admin-disallow-test blev blokeret som den skulle.
- Når du har rettet evt. fejl er vi klar til at uploade din robots.txt fil
- Gem din robots som .txt fil og navngiv den “robots.txt”
- Upload filen i din rodmappe via dit webhotel, FTP klient, eller hvordan du end foretrækker
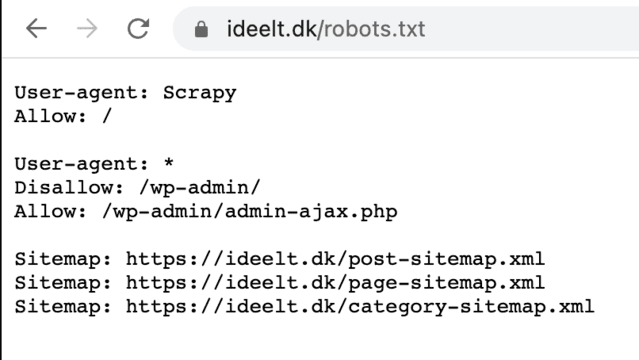
6. Gå til dit domænes robots.txt, og bekræft om den er live (f.eks. https://eksempel.dk/robots.txt alt efter dit domænes protokol og subdomæne):
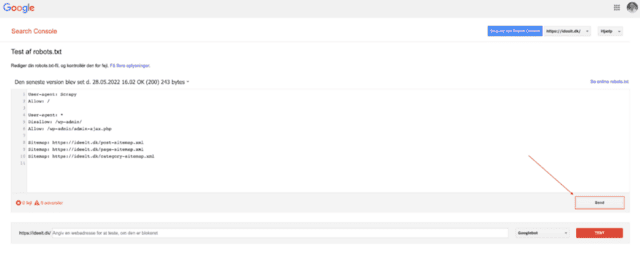
- Når du har sikret upload, går du tilbage til Google Search Console og vælger “Send”:
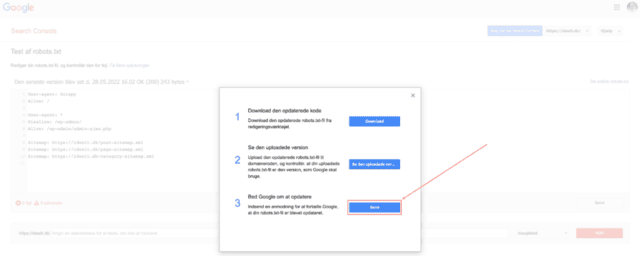
- Vælg “Send” under 3. punkt (anmoder Google om at opdatere):
- Det var det!
- Hvis Bing er en vigtig søgemaskine for dig, har de et næsten identisk værktøj her, hvor du blot kan kopiere denne proces
- Hvis du i fremtiden skulle ændre noget i din robots.txt fil, kan du med fordel gentage processen.
Det er ikke et must, men det kan hjælpe søgemaskinerne til at indlæse ændringerne hurtigere.
God fornøjelse!

Må jeg sende dig mine bedste SEO guldkorn? 🏆📈
Tilmeld dig mit nyhedsbrev, og hold dig opdateret på (dansk) SEO.
Jeg gør det altid kort og godt, da jeg ved du har andre ting at se til.
